
 X
X Facebook
Facebook LinkedIn
LinkedIn Reddit
Reddit Bluesky
BlueskyPrompt engineering for structured data: a comparative evaluation of styles and LLM performance
- Volume
- CitationElnashar A, White J, Schmidt D. Prompt engineering for structured data: a comparative evaluation of styles and LLM performance. Artif. Intell. Auton. Syst. 2025(2):0009, https://doi.org/10.55092/aias20250009.
- DOI10.55092/aias20250009
- CopyrightCopyright2025 by the authors. Published by ELSP.
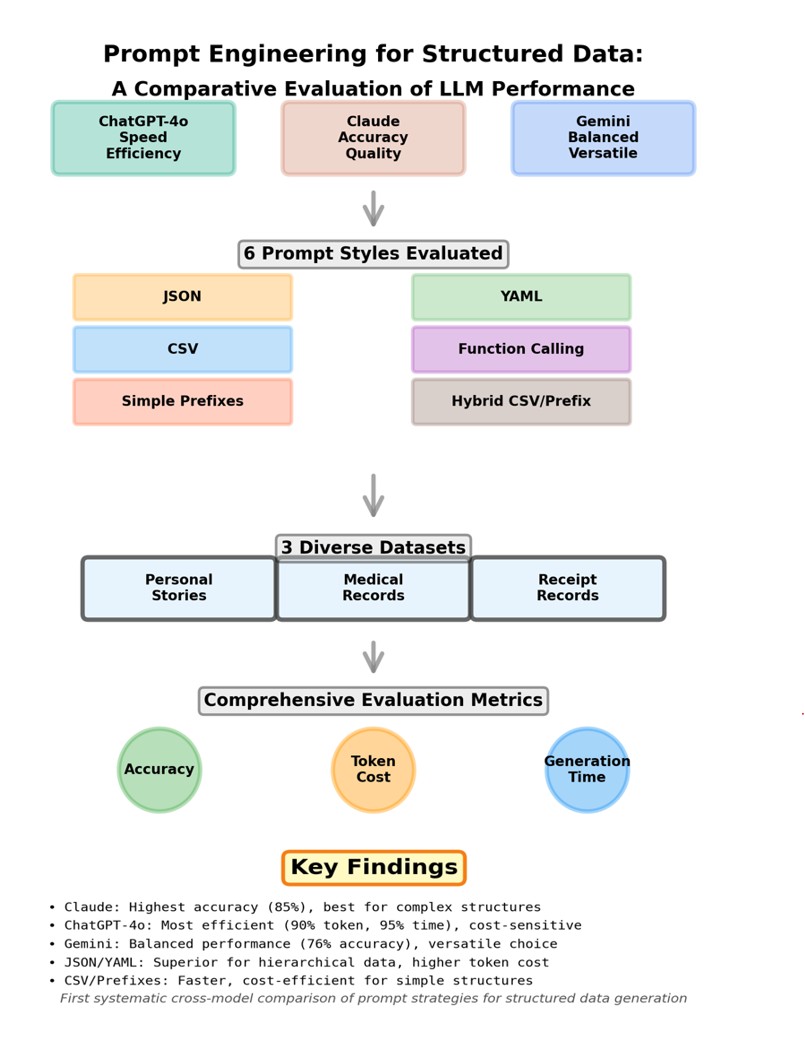
Prompt engineering for structured data is an evolving challenge as large language models (LLMs) grow in sophistication. Earlier studies, including prior work by the authors, tested only a limited set of prompts on a single model such as GPT-4o. This paper broadens the scope by evaluating six styles—JSON, YAML, CSV, function-calling APIs, simple prefixes, and a hybrid CSV/prefix—across three leading LLMs: ChatGPT-4o, Claude, and Gemini. Using controlled datasets, we benchmark accuracy, token cost, and generation time to deliver the first systematic cross-model comparison of prompt strategies for structured outputs. Our approach employs structured validation and custom Python utilities to ensure reproducibility, with results visualized through Technique vs. Accuracy, Token Cost, and Time graphs. Our analysis reveals clear trade-offs: simpler formats often reduce cost and runtime with little accuracy loss, while more expressive formats offer flexibility for complex data. These findings underscore how prompt design can be tuned to balance efficiency and versatility in real-world applications. Our results show prompt choice directly shapes both quality and efficiency. Claude consistently achieves the highest accuracy, ChatGPT-4o excels in speed and token economy, and Gemini provides a balanced middle ground. By extending beyond single-model evaluations, this study offers practical guidance for selecting prompts based on model capabilities and application demands, advancing prompt engineering with a comprehensive, multi-model framework for optimizing structured data generation.
structured data generation; LLMs; prompt engineering; JSON; YAML; CSV formats; token efficiency; data validation; cost-effective AI
