 X
X Facebook
Facebook LinkedIn
LinkedIn Reddit
Reddit Bluesky
BlueskyTLA: tactile-language-action model for contact-rich manipulation
- Volume
- CitationHao P, Zhang C, Li D, Cao X, Hao X, et al. TLA: tactile-language-action model for contact-rich manipulation. Robot Learn. 2026(1):0001, https://doi.org/10.55092/rl20260001.
- DOI10.55092/rl20260001
- CopyrightCopyright2026 by the authors. Published by ELSP.
- Special Issue
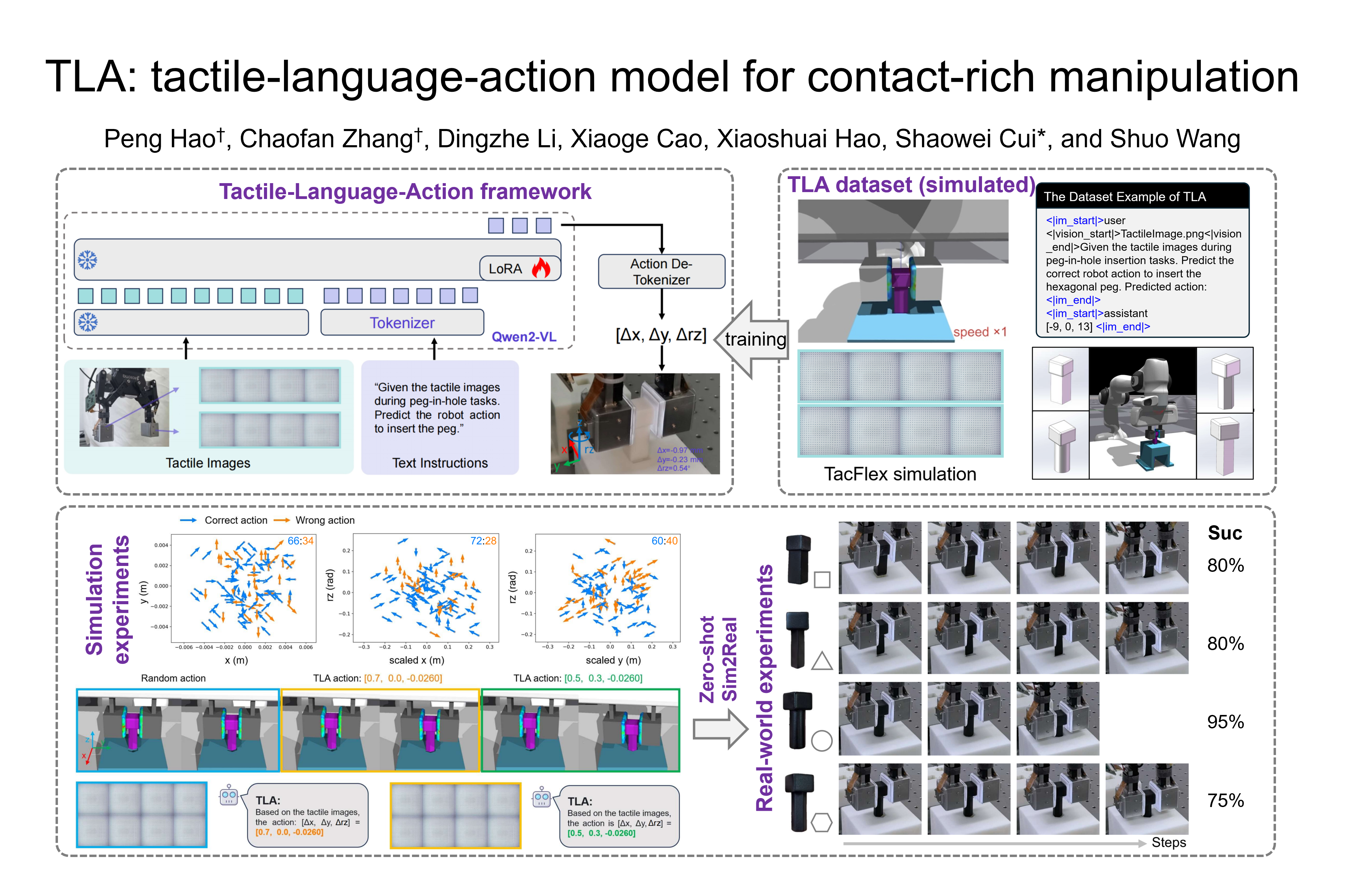
Significant progress has been made in vision-language models. However, language-conditioned robotic manipulation for contact-rich tasks remains underexplored, particularly with respect to tactile sensing. To address this gap, we propose the Tactile-Language-Action (TLA) model, which processes sequential tactile feedback through cross-modal language grounding to enable robust policy generation in contact-intensive scenarios. We also construct a large-scale and low-cost dataset comprising 24 k pairs of tactile-action instructions in simulation, tailored for fingertip-based peg-in-hole assembly. Experimental results show that TLA significantly outperforms traditional imitation learning methods (e.g., diffusion policy) in terms of action accuracy. Moreover, robotic insertion experiments demonstrate that TLA generalizes well to unseen peg shapes and clearances, achieving a success rate exceeding 85%, and achieves zero-shot sim-to-real transfer for real-world deployment. Project website: https://sites.google.com/view/tactile-language-action/.
vision-language-action model; tactile perception; contact-rich manipulation
