
 X
X Facebook
Facebook LinkedIn
LinkedIn Reddit
Reddit Bluesky
BlueskyAutomatic estimation and evaluation of multi-objective human preferences for Learning from Demonstration
- Volume
- CitationHertel B, Nguyen T, Cabrera ME, Azadeh R. Automatic estimation and evaluation of multi-objective human preferences for Learning from Demonstration. Robot Learn. 2026(1):0006, https://doi.org/10.55092/rl20260006.
- DOI10.55092/rl20260006
- CopyrightCopyright2026 by the authors. Published by ELSP.
- Special Issue
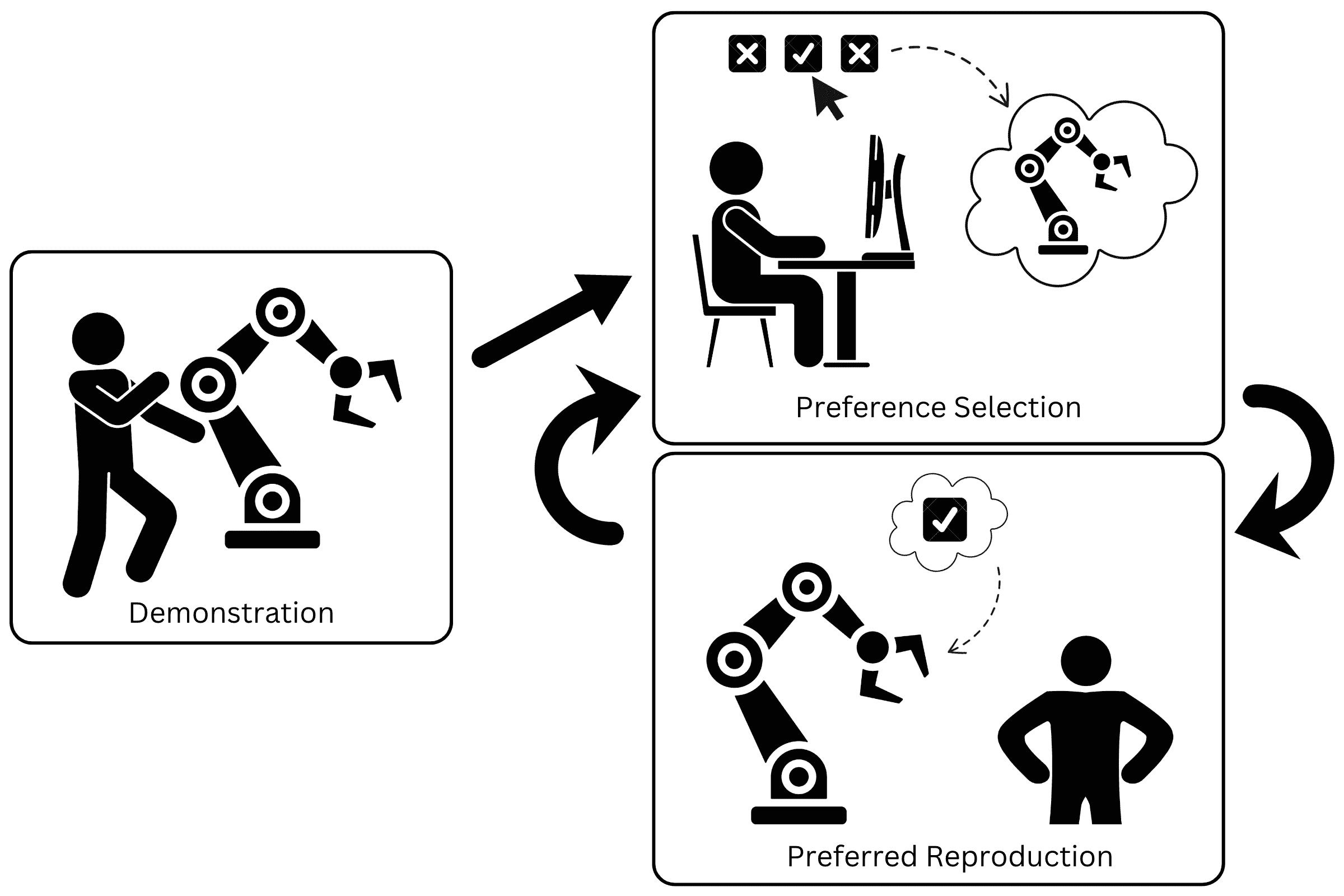
When robots are in the hands of end-users, they should perform tasks according to the preferences of those users. However, it is currently impractical to discover the preferences from those end-users without user-specific and task-specific feedback. To remedy this, we design and test an interface which can learn user preferences over time, eventually predicting their preference for the execution of any given task. Additionally, we collect data on user preferences from these interactions, aiming to find an overall preference of execution across tasks and across users. We validate several assumptions on user preference in a study (N = 10) which presents limited preference options to users. This validates our use of Pareto front options and choice of objectives in optimization. With the knowledge from this small study, we use an interface to let users explore their preference space for several unique tasks in a larger user study (N = 20). Our contributions include: (a) a novel Learning from Demonstration formulation for generating preference-aligned skill reproductions via multi-objective optimization, (b) a Graphical User Interface (GUI) for human-in-the-loop preference discovery, and (c) an analysis of inferred preferences across users and tasks. Through this analysis we find that individual users and tasks have specific preferences, but certain trends can be highlighted, like the desire for smooth and optimal robot execution.
human-robot interaction; Learning from Demonstration; preference learning; human-in-the-loop interaction; multi-objective optimization
